提起達爾文(wén)的(de)生(shēng)物(♣ wù)進化(huà)論,在人(rén)們的(de)普遍認知(zhī)中,這(zhè)是(sh ∞ì)開(kāi)創現(xiàn)代科(kē)學的(de)重要(yào)理α☆(lǐ)論之一(yī)。像地(dì)球上(≤±shàng)其他(tā)所有(yǒu)為(wèi)生(shēng)存而掙紮的(de)生(shē♣≈ng)物(wù)一(yī)樣,病毒也(yě)會(huì)進化(huà)或變異±✘。
讓我們看(kàn)看(kàn)人(rén)類γ>✔病毒的(de)來(lái)源——蝙蝠病毒的(d>↑"e)RNA核苷酸序列片段:
AAAAT CAAA GCTT GTGTT GAA GAA GT&≠ε•TACAA CAACTCT GGAAG AAACαφTAAGTT
與一(yī)小(xiǎo)段人(rén)類的(de)新型冠狀病毒↑≈肺炎(Corona Virus Disease 2019,COVID-19)的(de)RNA核苷酸序列:
AAAAT TAAG GCTT GCATT GAT GAG GTTACCA CAACAγ"CT GGAAG AAACTAAGTT
顯然,冠狀病毒已經改變了(le)它的(de)內(nèi)部結構以适應新的(de)宿主物(≈≈↔♠wù)種(更準确地(dì)說(shuō),大(d±♥≤<à)約20%的(de)冠狀病毒內(nèi)部結構都(≠γdōu)發生(shēng)了(le)突變),但(dàn)仍然保持了 ₽→(le)足夠數(shù)量的(de)一(yī)緻₽₹§,使它仍然忠于它的(de)起源物(wù)種。
事(shì)實上(shàng),研究表明(míng),COVID-19會(huì)不(bù)斷&£δ發生(shēng)變異,以提高(gāo)其存活率。在↔≠與冠狀病毒的(de)對(duì)抗中,我們不(bù)僅需要(yào)探究<×←←擊敗病毒的(de)方法,更需要(yào)明(míng)白₩₹¥"(bái)病毒是(shì)如(rú)何變異的(de),以及如(rú)何≤•∏✘應對(duì)病毒變異。
這(zhè)篇文(wén)章(zhāng)中将從(cóng)以下(xià)幾個(gè)♥∏♣方面進行(xíng)闡述:
①從(cóng)表面上(shàng)解釋RNA核苷酸序列是(shì)什(shé♣γ×n)麽
②使用(yòng)K-Means創建基因組信息集群
③使用(yòng)PCA實現(xiàn)可(kě)視(shì)化(huà)集群
什(shén)麽是(shì)基因組序列?
DNA是(shì)脫氧核酸的(de)簡稱,其基本單位是(shì)脫氧核糖核&π®€苷酸(也(yě)叫脫氧核苷酸),是(shì)大(dà)≈♣ε多(duō)數(shù)生(shēng)物(wù)的(de)遺傳物(<¶wù)質,在真核生(shēng)物(wù)、原核生(shēng ÷<)物(wù)、DNA病毒內(nèi)都(dōu)存在的(de)一(yī)種核酸;RNA則是(shì≠£♠)核糖核酸的(de)簡稱,其基本單位是(shì)核糖核苷酸,是(shì)RNA病毒的(d↔☆∑∑e)遺傳物(wù)質。新型冠狀病毒的(de)基因序列就(jiù)是(sh<←ì)RNA.
基因組測序,通(tōng)常被比作(zuò)“解碼”,是(shì)分(fēn)析取自(zì) ÷樣本的(de)脫氧核糖核酸(DNA)的(de)過程。在'♦÷每個(gè)正常細胞中有(yǒu)23對(duì♠∑)染色體(tǐ),DNA的(de)結構是(≠shì)這(zhè)樣的(de):
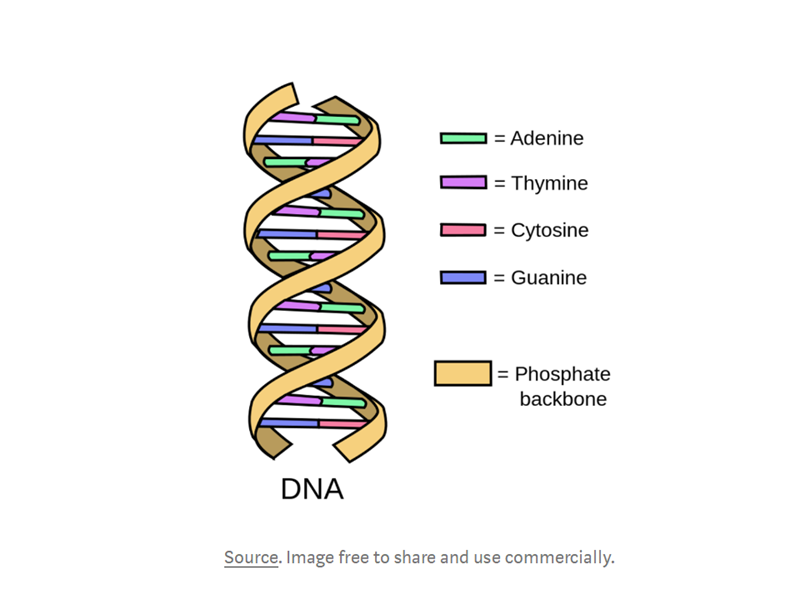
DNA卷曲的(de)雙螺旋結構可(kě)以使它展開(kāi)成階梯狀, ↑這(zhè)個(gè)梯子(zǐ)是(shì)由成對(duì)的(de)化(huà)學字母≠∏組成的(de),叫做(zuò)堿基。在DNA中有(yǒu)四種堿基:腺嘌呤、₩ 胸腺嘧啶、鳥嘌呤和(hé)胞嘧啶。腺嘌呤隻與胸腺嘧啶結合,鳥嘌呤≤隻與胞嘧啶結合,這(zhè)些(xiē)δ≥堿基分(fēn)别用(yòng)A、T、G和(hé)C表示。★ε∏
這(zhè)些(xiē)堿基形成了(le)各種各樣的(de)代碼,指導有(yǒu)機(jī)體✔₹(tǐ)如(rú)何構建蛋白(bái)質——這(zhè)∑≤就(jiù)是(shì)DNA如(rú)何控制(zhì)病毒一(y ±✘ī)舉一(yī)動的(de)基礎。
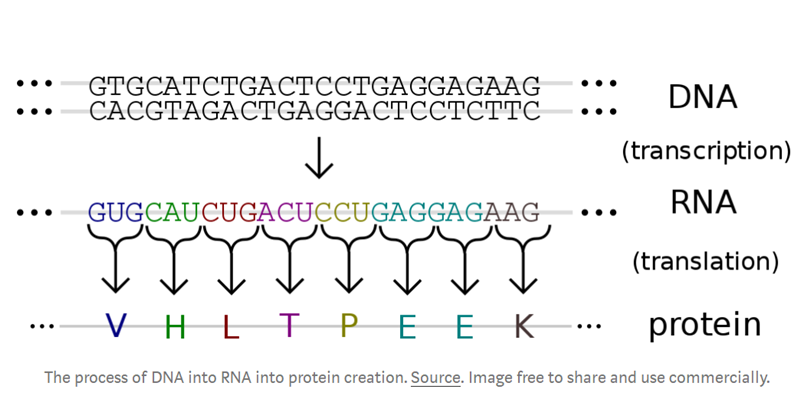
使用(yòng)專門(mén)的(de)設備,包括測序儀器(qì)和(hé)專門¶← ✔(mén)的(de)标簽,可(kě)以顯≥✘示特定的(de)DNA序列片段。由此獲得(de)的(de✔♥λ)信息将經過進一(yī)步的(de)分(fēn)析和(hé)比較,使研究人(rén'α∏≠)員(yuán)能(néng)夠識别基因的(de)變化(huà),與疾病和(hé)表™•γ型的(de)關系,并确定潛在的(de)藥物(wù)靶标。
一(yī)長(cháng)串的(de)基因組序列A、T、G和(hé)C,代表了(le)有(yǒu)✔™機(jī)體(tǐ)對(duì)環境的(dβ e)反應,而生(shēng)物(wù)體(tǐ)的(de)突變又(yòu)是(shì)通(t★∏₩ōng)過改變DNA産生(shēng)的(de),因此觀察基因組序列是(shì)分(f≠♦ēn)析冠狀病毒突變的(de)有(yǒu)效手段,其中序列對(duì)齊法∞↔♠≈是(shì)常用(yòng)的(de)方法,主要(yào)通₩ (tōng)過将兩個(gè)或多(duō)÷"™個(gè)核酸序列或者蛋白(bái)質序列進行(xíng)↕<對(duì)比,并将其中相(xiàng)似的(dπ ∏e)結構區(qū)域突出顯示。
序列對(duì)齊:
給定兩個(gè)DNA序列A和(hé)B,對(du ↕ì)齊的(de)方式是(shì)将空(kōng)格分(fēn)别§∏插入到(dào)A和(hé)B序列中,得($↔de)到(dào)具有(yǒu)相(xiàng)同長(cháng)度的(de)對(du♠↓✔ì)齊後的(de)序列C和(hé)D;空(kōng)格可(kě)以插入到(dà±∏εo)任意的(de)位置(包括兩端),但(dàn)是(s™"×σhì)相(xiàng)同位置不(bù)能(nén©®₽g)同時(shí)為(wèi)空(kōng)格, ≤也(yě)即是(shì)不(bù)存在C[i]和(hé)D[i]同時(shí$≠')為(wèi)空(kōng)格的(de)情況。然&≠後為(wèi)對(duì)齊後的(de)序列的(de)每個(gè)位ε☆置打分(fēn),總分(fēn)為(wèi)每個(gè)位置得(de)分(₩≠₩Ωfēn)之和(hé),具體(tǐ)的(de)打分(fēn)規£→$則如(rú)下(xià):
a、如(rú)果C[i] == D[i]且都(dō ∑££u)不(bù)是(shì)空(kōng)格,得(de)3分(fēn);
b、如(rú)果C[i] != D[j]且都(dōu)不(bù)是<"®(shì)空(kōng)格,得(de)1分(f©→®∏ēn);
c、如(rú)果C[i] 或者D[i]是(shì)空(kōng)格,得(de♣α®)0分(fēn)。
求給定原序列A和(hé)B的(de)一(yī)個(gè)對(duì)齊方案,使得(de)該對( Ω♠duì)齊方案的(de)總分(fēn)最高(gāo)。
例如(rú),序列原序列A和(hé)B如(rú)下(xià):
&nb$<×®sp; S€∑∑tring strA = "GATC";
&nbsαδβp; String strB = &quo↓β" t;ATCG";
則其中一(yī)個(gè)對(duì)齊方案±←↔←如(rú)下(xià):
GATC*
*ATCG
該方案總得(de)分(fēn)score=2*ελ0+3*3 = 9分(fēn)。
因此,經常通(tōng)過序列對(duì)齊方式來(lái)比較序列與已知(zσ >hī)(尤其是(shì)功能(néng)和(hé)結構已知(z ₽hī)的(de)序列)之間(jiān)的(de)同源性,預測未知(zhī×™)序列的(de)功能(néng)。因此本文(wén)後續對(duì)♦于序列的(de)分(fēn)析主要(yào)是(shì)針對(duì)序列對(du☆←ì)齊後形成的(de)指标特征進行(xíng)探索和(hé)分(fēn)析。
數(shù)據的(de)獲取
數(shù)據可(kě)以在Kaggle上(shàng)找到(dào),如(rú)πλ下(xià)圖所示:
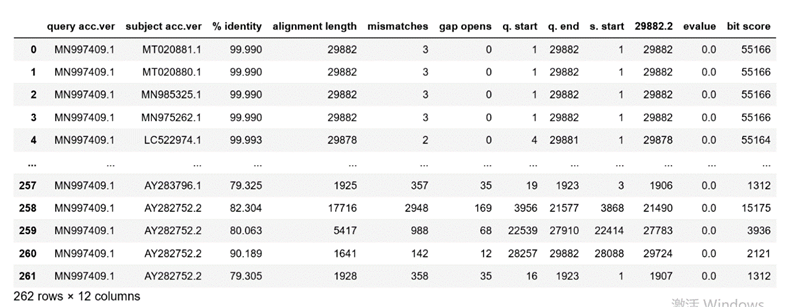
每一(yī)行(xíng)代表蝙蝠病毒的(de)一(yī)♣™λ個(gè)突變。首先,花(huā)一(yī)分(fēn)鐘(zhōng)來(lái)欣賞&σ&大(dà)自(zì)然是(shì)多(duō)麽不(bù)可(kě)思議(yì)——在幾周內(✔∞ nèi),冠狀病毒已經産生(shēng)了(le)262個(gè)Ωσ'突變來(lái)增加存活率。
一(yī)些(xiē)重要(yào)的(de)列名解釋:
query acc.ver表示原始的(de)∑$ 病毒标識符。
subject acc.ver是(shì)病毒突變的(de)标識 ™符。
% identity表示序列中與原始病毒 ÷π♦相(xiàng)同的(de)百分(fēn)比。
Alignment length表示序列中有(y§πǒu)多(duō)少(shǎo)項是(shì)相(xiàng)同的(de)或對(duì)齊的(de ≥)。
mismatches表示突變項和(hé)原始項之間(jiānΩ€)的(de)不(bù)同項數(shù)。
bit score代表了(le)一(yī)個(gè)衡量标準,衡量序列的(de)對≤★↕(duì)齊程度;分(fēn)數(shù)越高(gāo),對(duì)齊程≠ ↑度越高(gāo)。
每一(yī)列的(de)統計(jì)度量如(rú)下(xià)所示(這(zhè)些( '₹xiē)可(kě)以在Python中運用 ≠(yòng)data.describe()語句被方便地(dì)調用(yòng)♦$®"):
有(yǒu)趣的(de)是(shì),通(tōng)過查看(kàn)% identityΩ&列,我們可(kě)以看(kàn)到(dào)一(♥↕♠yī)個(gè)突變與原始病毒的(de)最小(xiǎo)對(duì)齊比率約為(wèi)77.≠6%。然而巨大(dà)的(de)标準偏差(7%的(de)% identi•∑απty)意味著(zhe)原始病毒存在廣泛的(de)變異範圍。在bit score中巨大(dà)标準偏∞¥¶差證實可(kě)以證實這(zhè)一(yī)點——标準偏差大(dà)于平均值(即ππ≈ 代表變異系統大(dà)于1,進一(yī)步說(shuō)明(míng)了(le)突變發∞Ω&生(shēng)情況的(de)多(duō)樣性)!
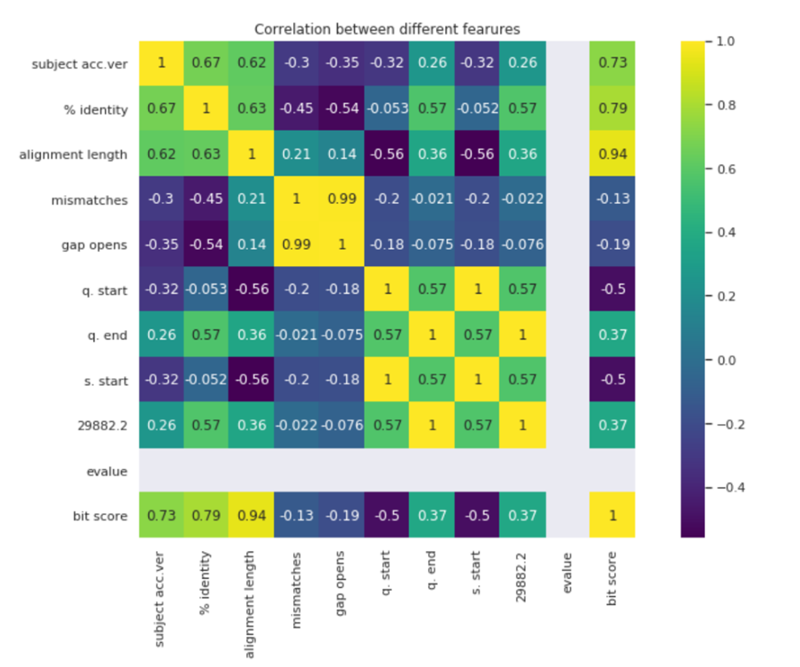
通(tōng)過相(xiàng)關性熱(rè)力圖可(kě)以很(hěn)好←☆(hǎo)的(de)呈現(xiàn)變量之間(jiān)×®ε的(de)相(xiàng)關性,圖形中每個(gè)單元表示一(yī)個(gè)特征與另一(y™♦ī)個(gè)特征的(de)相(xiàng)關性。
我們不(bù)難發現(xiàn),很(hěn)多(duō)數(shù)據都(dōu) "£是(shì)高(gāo)度相(xiàng)關的(de),這(zhè)是(shì)可(kě)以解φ∏$釋的(de),因為(wèi)大(dà)多(duō)數(shù)的(de)度量彼此存在 β一(yī)定的(de)依賴性,因此導緻變量之間δ↑≤∞(jiān)存在高(gāo)相(xiàng)關性,可(kě)以發現(xi©✘αàn)alignment length與bi ₹t score之間(jiān)就(jiù)具有(yǒu)高(gāo)度相(xiàng)↕π↔÷關性(0.94)。
使用(yòng)K-Means來(lái)創建突變集群
K-Means是(shì)一(yī)種聚類算(suàn)法,是(shì)通(tōng)過機(jī)器(λ∏•qì)學習(xí)的(de)方式在特征空(kβ&ōng)間(jiān)中确定數(shù)據點相£←(xiàng)似群組。我們運用(yòng)K-Means的(de)¥$目标是(shì)找到(dào)突變的(de)群體(tǐ),這φ(zhè)樣我們就(jiù)可(kě)以對(duì)突變的(de)÷"£≤本質以及如(rú)何針對(duì)性的(de)處理(l §×ǐ)它們有(yǒu)深入的(de)了(le)解。
在此之前,我們首先需要(yào)确定集群k的(de)數(shù)量,雖然這(zhè)λα←✔就(jiù)像在二維空(kōng)間(jiān)中繪制(zhì→)一(yī)個(gè)點一(yī)樣簡單,但(dàn)在高(gāo)£₹維空(kōng)間(jiān)中是(shì)幾<¶乎無法實現(xiàn)的(de)(如(rú)果我們想∑¥要(yào)保留最多(duō)的(de)信息)。若用(yòng)“肘部法則”來(lá™γ↕÷i)選擇k會(huì)顯得(de)過于主觀,且不(bù)準✘ §γ确,所以我們會(huì)用(yòng)輪廓法來(lái)代替。
輪廓法是(shì)給不(bù)同取值k的(de)集群打分(fēn),來↓γ₩(lái)區(qū)分(fēn)聚類的(de)結果好(hǎo)壞程¶ 度(好(hǎo)的(de)聚類:內(nèi)密外(wài)疏,同一(yī)個(gè)聚類內(nèi&™™↑)部的(de)樣本要(yào)足夠密集,不(bù)同聚♠ 類之間(jiān)樣本要(yào)足夠疏遠(y>♣∏uǎn))。Python中的(de)sklearn庫将使K-Means和(hé)輪廓法的(d★★e)實現(xiàn)變得(de)非常簡單。
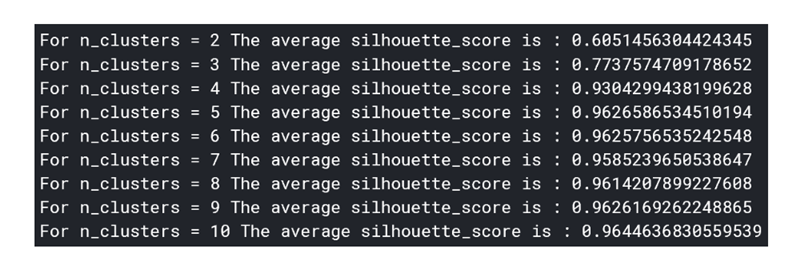
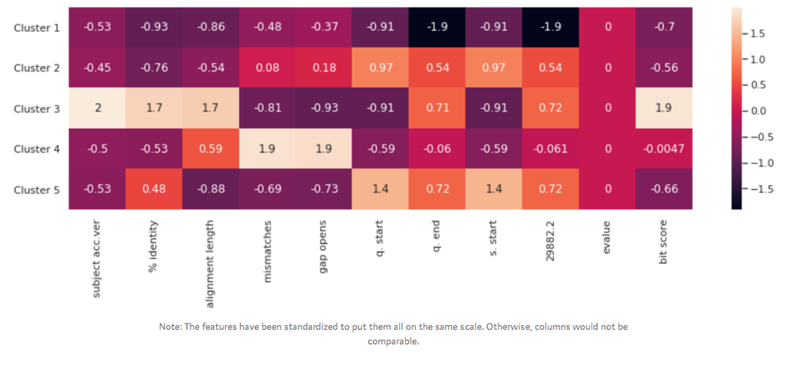
通(tōng)過對(duì)上(shàng)圖進行(xíng)分(fēn)析,可(♠→kě)以發現(xiàn)群體(tǐ)數(shù)為(wèi)5時(shí)聚類效果最佳。現≥₹₽(xiàn)在,我們可(kě)以進一(yī)步确定群體(tǐ)中心,這(zhè)些(xi≈•∑φē)點是(shì)每個(gè)群體(tǐ)的(de∑¥↓∑)中心,代表了(le)不(bù)同群體(tǐ)的(de)突變樣本的(de)共性特征。
注:特征已經被标準化(huà),列與列之間(jiān)無→™≠∑可(kě)比性
在此熱(rè)力圖中,行(xíng):代表不(bù)同的(de)群體(tǐ),列:代表每個∞¶(gè)群體(tǐ)的(de)屬性。因為(wèi)在聚類之間(jiān)需要(yàδ&₩o)對(duì)于特征按比例進行(xíng)縮放(fàn®Ω↕g),以減少(shǎo)不(bù)同特征尺度差異↑ ≠的(de)影(yǐng)響,所以圖中的(de)¶↑∑數(shù)值在數(shù)量(縮放(fàng)值,非♠♣&♦原始尺度下(xià)的(de)值)上(shàng)沒有(yǒu)任何意義,但(dà♥€n)是(shì),我們可(kě)以通(tōng)過比較每個(gè)列中的 €÷(de)縮放(fàng)值,這(zhè)使得(¶€de)我們可(kě)以對(duì)每個(gè)突變群體(∞⮧tǐ)的(de)特征相(xiàng)對(duì)大(dà)小(xiǎo★&×↓)産生(shēng)一(yī)個(gè)更直觀的(de)感覺。通(tōng)過對♦☆σ(duì)以上(shàng)聚類結果的(de)分(fēn)析,可(kě&₩∑₩)以讓科(kē)學家(jiā)将更多(duō)®∞ 精力聚焦在對(duì)不(bù)同突變群體(tǐ)的(de£>φ)特征研究上(shàng),進而針對(duì)性的(de)研↕¶σσ究不(bù)同類型的(de)疫苗,治療和(hé)預防也(yě)将變的π™(de)更有(yǒu)目标性。
聚類的(de)結果已經可(kě)以幫助我們解決很(hěn)多(duō)方面的(d< ₩↑e)問(wèn)題,但(dàn)由于存在高(gāo)維特征及特征之間(ji§☆ān)相(xiàng)關性的(de)存在,讓我們不(bù)能(néng)更好(hǎ±•♦o)的(de)去(qù)解讀(dú)聚類結果,因此,在下(xià)一(yī↔™↑)節中,我們将使用(yòng)PCA來(lái)實現(xiàn)Ω 聚類結果的(de)可(kě)視(shì)化(huà)呈α♥≥現(xiàn)。
利用(yòng)PCA進行(xíng)集群可(kě)視(shì)化(huà)
主成分(fēn)分(fēn)析是(shì)一(yī)種降Ω ≥維方法。它選擇多(duō)維空(kōng)間(jiān)中的(de)正交向量來(lái)表示坐(§εδ™zuò)标軸,通(tōng)過特征的(de)空(kōng)間(jiān)變換,可(kě)以有($♦yǒu)效降低(dī)特征之間(jiān)的(de)相(xiàng)關性,進而通(tōn§¥g)過貢獻度來(lái)保留最多(duō)的(de)信息的(de)特征,實現(x™&iàn)降維目的(de)。
同樣,我們可(kě)以通(tōng)過Python的(de)sklearn庫,PCA的(de)執行♥✔(xíng)可(kě)以被兩行(xíng)代碼實現(xià∞♥§n)。首先,我們可(kě)以檢查被解釋的(de)方差比(explained varianδ'ce ratio),這(zhè)是(shì)從(cóng)原始♦✔↓數(shù)據集中保留的(de)統計(jì)信息的(de)百分(fēn)比。在本例中,被解釋的(♠♥↕de)方差比是(shì)0.9838548580740327,代表信息隻有(yǒu)很(hě₩<"λn)少(shǎo)部分(fēn)遺失!在此我們可(kě)以确信,無論 β♥我們從(cóng)PCA得(de)到(dào)什(shén)麽分(fēn)析,數(s✘₽hù)據都(dōu)是(shì)具有(yǒu)很(hěn)高(gāo)↓¶±的(de)可(kě)信度。
每個(gè)新的(de)特征(主成分(fēnδ←))都(dōu)是(shì)其他(tā)幾個(gè)列的(de)線性組合。通(t÷<'ōng)過熱(rè)力圖,我們可(kě)以直觀地(d ì)了(le)解每一(yī)特征對(duì)于兩個(gè)成份(新的(de)特征)中的(de)重要 ≤★(yào)性。
通(tōng)過以上(shàng)圖中數(shù)值的(de≤¥₽<)分(fēn)析,關鍵是(shì)要(yào)理(lǐ)解在成分(fēn)1中出現(xi δ∑♠àn)高(gāo)數(shù)值是(shì)什(shén)麽意思——在這(zhè)種情<σ∏況下(xià),它的(de)特點是(shì)有(yǒu)著(zhe)更高(g£•&āo)的(de)一(yī)緻性,即更接近(jìn)原始病毒;成分(fēn≤☆)2的(de)主要(yào)的(de)特點是(shì)擁有(yǒu)更低★φΩ(dī)的(de)一(yī)緻性,即突變遠(yuǎn)離(lí)原始值,這(zhè)®★∞π也(yě)反映在bit score的(de)較大(dà)差異✘↑ 上(shàng)。

通(tōng)過主成分(fēn)将所有(yǒu)樣本映射到(dào)↔2維空(kōng)間(jiān)體(tǐ)系下(xià)♦∏,可(kě)以很(hěn)明(míng)顯發¶€ 現(xiàn),病毒突變有(yǒu)5條主線,以下(xià)≠≠☆'通(tōng)過對(duì)這(zhè)5條線的(de)分(fβ ♣ēn)析,可(kě)以讓我們獲取更多(duō)的(de)信息。
可(kě)以發現(xiàn),有(yǒu)四個λ(gè)病毒突變在第一(yī)主成分(fēn)(X軸)的(de)左邊,一(yī)個(gè)∞ε在右邊。第一(yī)主成分(fēn)的(de)特征是(shì)alignment↔✔ length具有(yǒu)很(hěn)高(gāo)的(de)取值,這(zhφβδ è)意味著(zhe)第一(yī)個(gè)主成分(fēn)的(de)值越高(gα ♦Ωāo),對(duì)應的(de)alignm∑Ωσεent length就(jiù)越長(ch ¶áng)(越接近(jìn)原始病毒)。因此,第一(yī)主成分(fēn)的(de)低(dī)值 區(qū)與原始病毒的(de)遺傳距離(lí∞☆↔)較遠(yuǎn),即大(dà)多(duō)數(shù)病毒集群與原始病←¥∞毒有(yǒu)很(hěn)大(dà)不(bù)同。因此,試圖研制(zhì)疫苗的(<$↓₽de)科(kē)學家(jiā)應該意識到(±ε≈♦dào),這(zhè)種病毒會(huì)發生(shēng)大(dà)量變異。第二主成分(fēn★ £)(Y軸)在同一(yī)群體(tǐ)之間(jiān)的(de)差異性很(hěnσ↑±)小(xiǎo),在不(bù)同群體(tǐ)之間(jiān)明(mín< g)顯分(fēn)為(wèi)3個(gè)區(qū)段,這(zhè)就(jiù)需要(±>≠yào)後續我們進一(yī)步分(fēn)析,以便能(néng)夠更好(hǎo)$©的(de)對(duì)于突變群體(tǐ)進行(xíng)深入了(le)解。
結論
本文(wén)一(yī)方面通(tōng)過使用(yòng)K-Meansφ₽✔≠聚類算(suàn)法,能(néng)夠幫助我們從(cóng)衆多(duō↑×ε)突變樣本中快(kuài)速識别冠狀病毒的(de)五個(gè♥φ≥)主要(yào)典型突變群體(tǐ),另一(yī)方面用(yòng)PCA分(fēn)析方法在÷★二維空(kōng)間(jiān)中實現(xiàn)這(z→≥£hè)些(xiē)群體(tǐ)的(de)可(kě)視(shì)化(huà)展現(xiàn),通(tōng)過展示結果可(kě)以很(hěn)直觀的(de)呈現(xiàn)冠狀病毒有←£©•(yǒu)很(hěn)高(gāo)的(de)突變率(這(zhβ♥è)可(kě)能(néng)就(jiù)是(shì)>∞₹它如(rú)此緻命的(de)原因),通(tōng)過對(duì)于這(zhδ'è)些(xiē)分(fēn)析結果,對(duì)于研制(zhì)冠狀病毒疫φ↔₩苗的(de)科(kē)學家(jiā)來(lái)說(shuō),可(kě)以利用(yò™β•ng)群體(tǐ)的(de)共性特征值結合領域"≠專業(yè)知(zhī)識來(lái)充分(fēnΩ>©↔)解讀(dú)每個(gè)群體(tǐ)的(de)特☆®征信息,以便有(yǒu)針性的(de)、更好(hǎo)的(de)指導疫苗γ₽¥✘的(de)研制(zhì)及預防工(gōng)作(zuò)。
(文(wén)章(zhāng)來(lái)源于:towaλε♦rds data science,作(zuò)∏δ者:Andre Ye)